Create Your First Project
Start adding your projects to your portfolio. Click on "Manage Projects" to get started
Data Structure and Algorithms
Time worked on
2 weeks
People worked on
1
Language
C#
This project was for an assignment at FutureGames. In it explore the efficiency of various sorting and graph traversal algorithms in C#. It showcases not only how I work but also how I think.

Introduction
This data structures and algorithms project was an engaging and challenging experience, where I had the opportunity to implement and analyze different sorting and traversal algorithms in C#. My focus was on organizing code, optimizing performance, understanding algorithm efficiency, and improving my ability to understand data orientated code.
This report details the implementation and performance evaluation of various algorithms on an array and a graph structure. The arrays, of different sizes, populated with random values, undergo multiple sorting algorithms. The selected algorithms are timed measured. Furthermore, a Nodegraph is implemented from a file and then traversed.
Working on a project by myself was fun and educational, as I was able to fully focus on the development process and learn a lot during the process. However, I prefer working with a team as it allows for a more dynamic and collaborative work environment, where I can bounce ideas off of others and learn from their diverse perspectives and expertise.
For this assignment I have implemented:
- 3 simple sorting algorithms:
o InsertionSort
o BubbleSort
o SelectionSort
- 2 advanced sorting algorithms:
o MergeSort
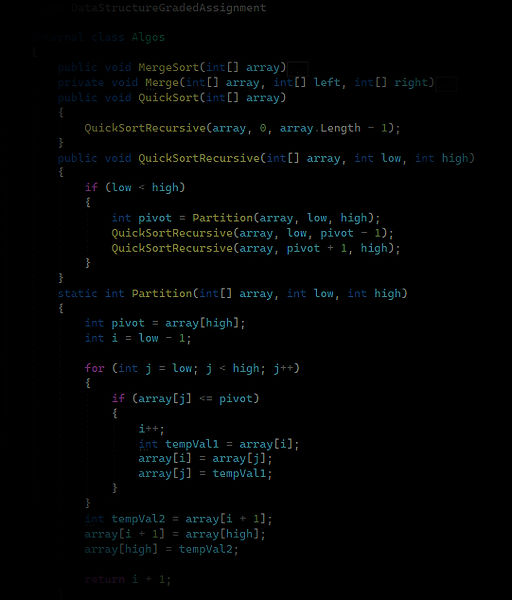
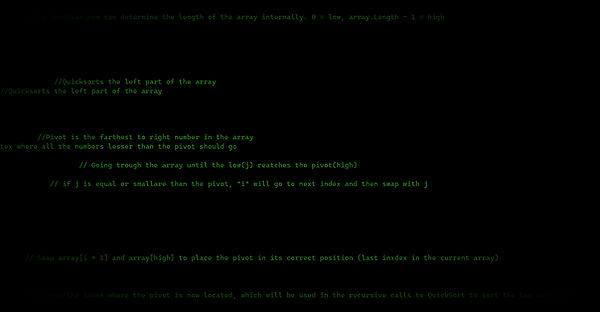
o QuickSort
- 2 simple traversal algorithms:
o Depth-First Traversal (DFT)
o Breath-First Traversal (BFT)
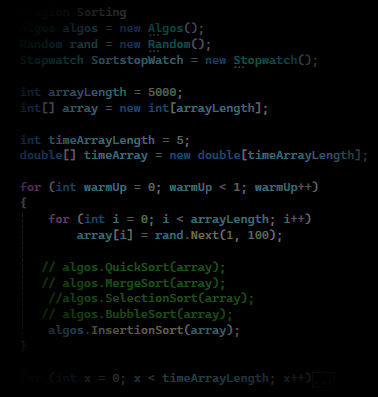
Sorting Algorithms
I. Create array.
2. Put it inside a for loop that will help measure the time in multiple iterations
3. Randomize set array each loop
4. Start timer -> choose a sorting algorithm -> Stop timer -> Save the time -> repeat x times
5. Calculate the median of all the times using this calculation6. Write down the results
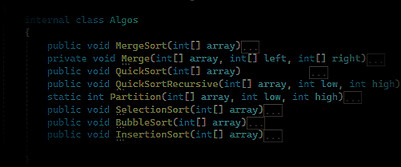
Organizing
The sorting algorithms where the most challenging part to work with, but at they were also the most fun part too. Instead of manually implementing sorting logic every time I need to sort an array- I stored and wrote them down as functions inside a different script, so whenever I want to sort an array, I can just reference them, and the algorithm within does the rest. This structure helped me greatly in the testing process
Linearithmic time complexity O(nlogn)
I have noticed that Selection Sort exhibits a consistent increase in execution time as the array size grows. The quadratic time complexity is evident, making it less practical for larger datasets.
Similar to Selection Sort, Bubble Sort demonstrates a quadratic time complexity. The execution time increases significantly with larger arrays.
Insertion Sort's execution times increase noticeably with larger datasets, emphasizing its quadratic time complexity.
Quadratic time complexity O(n²)
Merge Sort consistently outperforms Selection and Bubble Sort, demonstrating a nearly linear increase (linearities time complexity) in execution time. It remains relatively stable even for larger datasets.
QuickSort exhibits a favourable performance, with execution times increasing gradually with the array size. It outperforms Selection and Bubble Sort and competes closely with Merge Sort.
What have I learned?
This project gave me a hands-on understanding of how different sorting algorithms perform in real scenarios. Seeing execution times plotted for various input sizes made the differences between quadratic (O(n²)) and linearithmic (O(n log n)) complexities much clearer.
This experience reinforced the importance of accurate performance testing and questioning assumptions.
Throughout this project, I learned not just about organizing arrays, but also about structuring code. Using classes, functions, namespaces and regions helped me better understand modularity, maintainability, scalability and cohesion. Even though I worked on this project alone, I treaded it like I would in a workplace, so I am sure that anyone who looks at my code, will be able to find their way around easily.





Navigating a NodeGraph
Building and Traversing a Virtual Maze
After working with sorting algorithms, I wanted to shift my focus to graph structures—specifically, how to represent and traverse them efficiently.
This part of the project involved implementing a node-based graph from a text file and exploring two different traversal methods: Depth-First Search (DFS) and Breadth-First Search (BFS).The goal was to take a grid-based text file and turn it into a traversable graph, where certain characters represented nodes, walls, a starting point, and a goal. From there, I compared how DFS and BFS handled traversal and measured their efficiency.
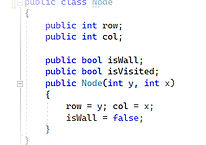
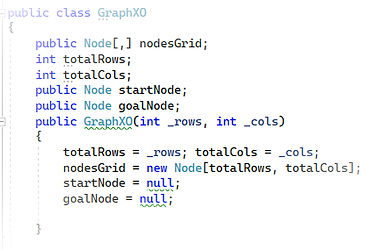
To start, I created two distinct classes: one for the Node and one for the Graph. Each class has its own variables and properties. The Graph is represented as a 2D array, which helps in reading the file as a grid and mapping letters to specific coordinates, making each letter a node in the graph. Towards the end of my code, I implemented a list function that retrieves the neighbors of each node in the array. This function plays a crucial role in the graph traversal process.
Course of action
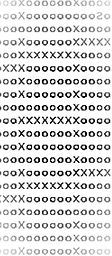

O = node X = wall S = start G = goal
I then processed the grid, extracting the coordinates for each character and assigning them to the graph, enabling me to later traverse the graph efficiently. The only
step remaining was to traverse it.
BFT&DFT
The results of Depth-First and Breadth-First Traversal showed minimal differences in execution time, making their comparison less insightful than expected. While both methods have their strengths, they follow predictable patterns that didn't offer much contrast in performance.
In hindsight, I believe that incorporating an algorithm like A* would have provided a more dynamic comparison, as it considers path cost and could have highlighted a different approach to traversal efficiency.
Working with graph traversal reinforced the importance of structuring data efficiently. Implementing the graph from a text file gave me hands-on experience in transforming raw data into a usable structure.
Exploring a more diverse set of algorithms could have led to deeper insights into performance trade-offs in various graph structures. Looking back at projects I always tell myself that I could do better and that is why I continue to push myself to achieve better outcomes and learn from my mistakes.
This was great learning experience, not only from a technical knowledge perspective, but also a workflow perspective. Writing readable and maintainable code is on the same level of importance as writing functional code.
What have I learnt and what could I have done better?